 Bytes curtos: O rastreador da Web é um programa que navega na Internet (World Wide Web) de maneira predeterminada, configurável e automatizada e executa determinada ação no conteúdo rastreado. Mecanismos de busca como Google e Yahoo usam spidering como meio de fornecer dados atualizados.
Bytes curtos: O rastreador da Web é um programa que navega na Internet (World Wide Web) de maneira predeterminada, configurável e automatizada e executa determinada ação no conteúdo rastreado. Mecanismos de busca como Google e Yahoo usam spidering como meio de fornecer dados atualizados.
A Webhose.io, uma empresa que fornece acesso direto a dados ao vivo de centenas de milhares de fóruns, notícias e blogs, em 12 de agosto de 2015, postou os artigos que descrevem um pequeno crawler multi-threaded escrito em python. Este rastreador da web python é capaz de rastrear toda a web para você. Ran Geva, o autor deste minúsculo rastreador da web python afirma que:
Escrevi como “Dirty”, “Iffy”, “Bad”, “Not very good”. Eu digo, ele faz o trabalho e baixa milhares de páginas de várias páginas em questão de horas. Nenhuma configuração é necessária, nenhuma importação externa, apenas execute o seguinte código Python com um site seed e relaxe (ou faça outra coisa porque pode levar algumas horas ou dias, dependendo de quantos dados você precisa).O rastreador multi-thread baseado em python é bastante simples e muito rápido. É capaz de detectar e eliminar links duplicados e salvar a origem e o link, que podem ser usados posteriormente na localização de links de entrada e saída para calcular a classificação da página. É totalmente gratuito e o código está listado abaixo:
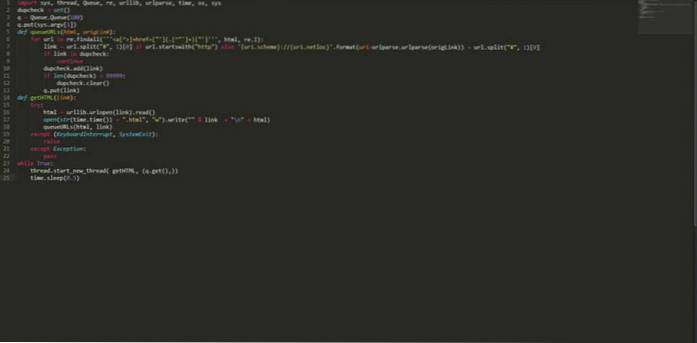
import sys, thread, Queue, re, urllib, urlparse, time, os, sys dupcheck = set () q = Queue.Queue (100) q.put (sys.argv [1]) def queueURLs (html, origLink): para url em re.findall ("] + href = ["'] (. [^"'] +) ["']", html, re.I): link = url.split ("#", 1) [0] if url.startswith ( "http") else 'uri.scheme: // uri.netloc' .format (uri = urlparse.urlparse (origLink)) + url.split ("#", 1) [0] se link em dupcheck : continue dupcheck.add (link) if len (dupcheck)> 99999: dupcheck.clear () q.put (link) def getHTML (link): try: html = urllib.urlopen (link) .read () open (str (time.time ()) + ".html", "w"). write (""% link + "\ n" + html) queueURLs (html, link) exceto (KeyboardInterrupt, SystemExit): aumentar exceto Exceção: pass enquanto True: thread.start_new_thread (getHTML, (q.get (),)) time.sleep (0,5) Salve o código acima com algum nome, digamos “myPythonCrawler.py”. Para começar a rastrear qualquer site, basta digitar:
$ python myPythonCrawler.py https://fossbytes.com
Sente-se e aproveite este rastreador da web em python. Ele fará o download de todo o site para você.
Torne-se um profissional em Python com estes cursos
Você gosta deste rastreador da web multi-threaded baseado em python morto simples? Deixe-nos saber nos comentários.
Leia também: Como criar USB inicializável sem qualquer software no Windows 10